







Full-text search by using Apache Lucene
Apache Lucene is a library that allows to organize a full-text search across multiple documents by the specified keywords. This article contains a brief overview of the library main features, and outlines its implementation on the C#.

Apache Lucene is a library that allows you to organize a full-text search across multiple documents (search by the specified keywords).
The main implementation of this library is written on Java. But there are also ports of the library to other languages and platforms: Lucene.Net, written in C #, CLucene (C ++) and others.
It is an open source library, licensed under the Apache License 2.0. The library also has a fairly detailed documentation. All this allows expanding its standard functionality.
This article describes a library implementation on the C# language.
Building a search index
The index is the major source of data in Lucene, which is used in the search process. The index is a data storage, which includes a number of documents. The main components of the documents are the data fields.
To build search index, you must create a set of documents with the corresponding values of fields and add these documents to the index.
The process of the index building is shown in Fig. 1.
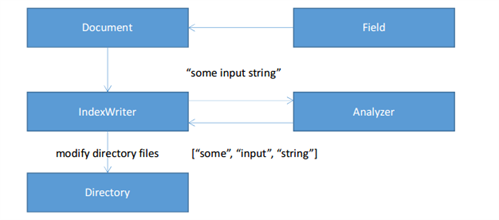
Fig. 1 Index building
When building the index, you need to specify the actual Analyzer and the Directory. Let us dwell on these classes.
The Directory is responsible for the storing of the data index. Formally, directory it is an abstract data storage that implements the specified interface. The interface includes methods for creating, modifying and deleting files. Each file has a name and content. Thus, the logic of the directory doesn’t depend on structure of the index. The most common implementations of this interface are the SimpleFSDirectory and RAMDirectory classes. They store the content of the index in the file system and RAM memory.
The analyzer is responsible for converting the values of the document fields in the set of tokens. An example of such transformation is shown in Fig. 1 Tokens are the keywords, which are conducted by the search.
IndexWriter is the link between these classes and it’s responsible for saving the data of the index documents, their fields and tokens by using the provided analyzer and directory.
Here is an example of code that builds an index for test products.
static void BuildIndex()
{
var sampleProducts = new[]
{
new Product { Id = 1, Name = "Gibson SG", Brand = "Gibson", Color = "Black" },
new Product { Id = 2, Name = "Ibanez S570", Brand = "Ibanez", Color = "Red" }
};
using (var directory = GetDirectory())
using (var analyzer = GetAnalyzer())
using (var writer = new IndexWriter(directory, analyzer, IndexWriter.MaxFieldLength.UNLIMITED))
{
writer.DeleteAll();
foreach (var product in sampleProducts)
{
var document = MapProduct(product);
writer.AddDocument(document);
}
}
}
static Document MapProduct(Product product)
{
var document = new Document();
document.Add(new NumericField("Id", Field.Store.YES, true).SetIntValue(product.Id));
document.Add(new Field("Name", product.Name, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Color", product.Color, Field.Store.YES, Field.Index.ANALYZED));
document.Add(new Field("Brand", product.Brand, Field.Store.YES, Field.Index.NOT_ANALYZED));
return document;
}
static Directory GetDirectory()
{
return new SimpleFSDirectory(new DirectoryInfo(@"D:\SampleIndex"));
}
static Analyzer GetAnalyzer()
{
return new StandardAnalyzer(Version.LUCENE_30);
}
Data Extracting
After the index is built it is possible to conduct a search. To do this, we need to create a search query. The search process is shown in Fig. 2 QueryParser converts the query string into a set of tokens with the help of Analyzer. Then IndexSearcher produces the search in the index directory and returns a set of documents as a result.
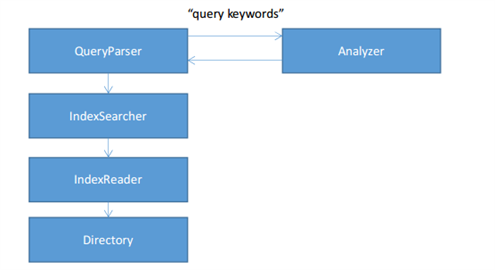
Fig. 2 Search by index
Building queries
Lucene library provides a wide set of classes for making searches. Here are some of them:
- TermQuery - search by keywords
- BooleanQuery – combination of several queries
- FuzzyQuery - search on inexact matching
- PhraseQuery - search on the order of keywords
- RegexQuery - regular expression search
Let’s consider the example of making a search query.
static Query GetQuery(string keywords)
{
using (var analyzer = GetAnalyzer())
{
var parser = new QueryParser(Version.LUCENE_30, "Name", analyzer);
var query = new BooleanQuery();
var keywordsQuery = parser.Parse(keywords);
var termQuery = new TermQuery(new Term("Brand", "Fender"));
var phraseQuery = new PhraseQuery();
phraseQuery.Add(new Term("Name", "electric"));
phraseQuery.Add(new Term("Name", "guitar"));
query.Add(keywordsQuery, Occur.MUST);
query.Add(termQuery, Occur.MUST_NOT);
query.Add(phraseQuery, Occur.SHOULD);
return query; // +Name:ibanez -Brand:Fender Name:"electric guitar"
}
}
In this example, you first create the query parser for the field Name. The analyzer is the same that was used when we were building the index. This parser creates a query to find passed keywords in Name. Then we create a query to search the word "Fender" in the Brand. Next step is to create an object PhraseQuery for the search of serial entry of specific words in Name. Created queries are combined by BooleanQuery: the first query condition must pass; the second must not. Passing the third query condition is optional, but it effects on the relevance of the document in the resulting issue.
As a result, we obtain a compound query that will be used in the search.
Sorting
When searching, you can specify sorting options. Documents can be sorted by the relevance (default), by the document number in the index or by one of the fields. You can also sort by the multiple fields, indicating their order.
There is an example of building the sorting object that sorts by two fields: by Brand, and then by the relevance.
static Sort GetSort()
{
var fields = new[]
{
new SortField("Brand", SortField.STRING),
SortField.FIELD_SCORE
};
return new Sort(fields); // sort by brand, then by score
}
Specifying the sort parameter is optional.
Filter
Also, when you do a search, you can use the filter mechanism. In general, it is similar to the mechanism of making queries. Often classes for creating filters have similar classes for creating queries. The main difference between the filter and queries is that it does not effect on the resulting relevance of documents: it only narrows the result.
Here is an example of creating a filter for the field Id: the result will include only documents with the field Id in the range [2; 5).
static Filter GetFilter()
{
return NumericRangeFilter.NewIntRange("Id", 2, 5, true, false); // [2; 5) range
}
The use of filter is also optional.
Search
After you defined a query, sorting options, and filter, you can perform the search itself. Below is an example of code that performs the search of the specified keywords in the previously created index, and outputting the results to the console.
static void Main()
{
BuildIndex();
int count;
var products = Search("Ibanez", 10, out count);
foreach (var product in products)
Console.WriteLine("ID={0}; Name={1}; Brand={2}; Color={3}", product.Id, product.Name, product.Brand, product.Color);
Console.WriteLine("Total: {0}", count);
Console.ReadKey();
}
static List Search(string keywords, int limit, out int count)
{
using (var directory = GetDirectory())
using (var searcher = new IndexSearcher(directory))
{
var query = GetQuery(keywords);
var sort = GetSort();
var filter = GetFilter();
var docs = searcher.Search(query, filter, limit, sort);
count = docs.TotalHits;
var products = new List();
foreach (var scoreDoc in docs.ScoreDocs)
{
var doc = searcher.Doc(scoreDoc.Doc);
var product = new Product
{
Id = int.Parse(doc.Get("Id")),
Name = doc.Get("Name"),
Brand = doc.Get("Brand"),
Color = doc.Get("Color")
};
products.Add(product);
}
return products;
}
}
In this example, search is performed by the keyword "Ibanez" with a limit of 10 documents. Search query, filter and sort are defined by the previously described functions. Next step is to retrieve fields of the found documents from the index and return them as a result. The result of the program is shown below.
ID=2; Name=Ibanez S570; Brand=Ibanez; Color=Red
Total: 1
Stemming
One of the useful tools that are used in the full text search is stemming. This mechanism allows you to bring different forms of the same word to the common form. For example, the word "guitar" and "guitars" - different forms of the same word. Without the use of this mechanism, they will be stored in the search index as different tokens, and queries for these words will return different results. If different forms of the same word bring to the one form, then the problem will be solved, and the queries will return the right result.
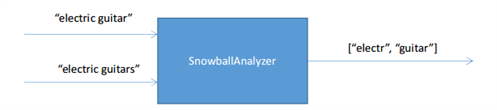
Fig. 3 The use of stemming-analyzer
There is a special analyzer in Lucene to support this feature. Let us dwell on how any analyzer operates in Lucene.
The input data for the analyzer is a stream of characters represented by the object Reader. This stream object is divided into a set of tokens by Tokenizer. Then this set passes through a group of filters. The number of filters could be any, including zero. Filters can add new tokens, modify, and delete existing ones. StopFilter can be an example of such filter, which allows you to exclude unnecessary words, (such as conjunctions, prepositions, articles) from indexing.

Fig. 4 Work of the analyzer
Another example of the filter is Stemming-filter. This filter converts each token to the general form and Stemming-analyzer returns a set of tokens that are converted to a common form.
Stemming is implemented as a class SnowballAnalyzer in an assembly Lucene.Net.Contrib.Snowball. You also must set the language for which stemming will be used. There are a lot of supported languages. But standard implementation does not provide the ability to use multilingual stemming.
Spellchecker
Another useful tool in the full-text search is Spellchecker. Firstly, it lets you find an error in a query. It also allows you to create a list of query corrections, similar in spelling to the original.
This functionality is implemented in an assembly Lucene.Net.Contrib.SpellChecker. You first need to build an index that will be a kind of dictionary. Using this dictionary, we can check query keywords: if they are not presented in the dictionary, it will be a misspell with a high probability. Further, this index can be used for the searching of the words that are closest in spelling to the original.
Let us consider in details the search mechanism of similar in spelling words.
First we need to perform rough search using n-gram mechanism. This is an approach, in which the words for indexing are divided into groups of 2 letters, 3 letters, and so on. These groups are an “n-grams”. Example of an “n-grams” for the word “lettuce” is shown in Fig. 5.

Fig. 5 Splitting words in the n-grams
As we could see the list of n-grams we got for the word with the typo is quite close to the n-grams list for the original word. Do note however that such criteria is not accurate and only used to narrow the initial selection in order to compare words more precisely. After that words from a narrowed selection got compared to the original by computing so called Levenshtein distance - a value which shows a total number of character deletions, insertions, or substitutions required to transform one word to the other word. Results with the minimum value of Levenshtein distance are the words which are pretty close to the original word.
Conclusion
The article contains a brief overview of the main features of Lucene.
Lucene provides not only a wide range of built-in tools for full-text search, but also a lot of ways to customize the search process.
Apache Lucene is still used but mostly in some legacy projects. WaveAccess developers haven’t been using this library directly in any of their projects for many years. It was replaced by new products based on it - Elasticsearch and Solr. These Open Source search engines are the most popular ones in 2022. Learn about the capabilities and mechanisms of the platform in the article “Service for text search "Solr".

